
AWS Glueデータカタログへのテーブルの作成とAthenaでのクエリ実行をAWS CLIでやってみた

こんにちは、CX事業本部の若槻です。
AWSでデータ分析を行いたい場合は、Amazon S3上などのデータをAWS Glueのデータカタログに登録し、Amazon Athenaでそのデータカタログをクエリして分析に用いる、という方法がよく取られます。
今回は、AWS Glueデータカタログへのテーブル作成とAthenaでのクエリ実行をAWS CLIでやってみました。
やってみる
S3バケットとデータの準備
データカタログに登録するデータソースとなるS3バケットおよびデータを準備します。
バケット作成
% aws s3 mb s3://<bucket-name>
データ作成
% touch data.csv
rank,name,attribute 1,hojo,Co 2,sagisawa,Co 3,ichinose,Cu 4,kamiya,Co 5,takagaki,Co
データをS3にアップロード
% aws s3 cp data.csv s3://<bucket-name>/data/data.csv
Glueデータカタログへのテーブルの作成
データベース作成
create-databaseコマンドを実行してテーブルの作成先となるデータベースを作成します。
% aws glue create-database --database-input "{\"Name\":\"tempdb\"}"
テーブル作成
作成するテーブルのテーブルプロパティをファイルで定義します。
% touch tableinput.json
<bucket-name>は先程作成したバケット名を指定します。
{
"Name": "s3-output",
"StorageDescriptor": {
"Columns": [
{
"Name": "rank",
"Type": "int"
},
{
"Name": "name",
"Type": "string"
},
{
"Name": "attribute",
"Type": "string"
}
],
"Location": "s3://<bucket-name>/data",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"SerdeInfo": {
"SerializationLibrary": "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe",
"Parameters": {
"field.delim": ",",
"serialization.format": ","
}
}
},
"Parameters": {
"skip.header.line.count": "1",
"EXTERNAL": "TRUE",
"has_encrypted_data": "false",
"serialization.encoding": "utf-8"
}
}
create-tableコマンドを実行して、テーブルプロパティをもとにテーブルを作成します。
% tableinput=$(cat tableinput.json) % aws glue create-table --database-name tempdb --table-input $tableinput
つまずきポイント
テーブルプロパティで、入力フォーマット(StorageDescriptor.InputFormat)および出力フォーマット(StorageDescriptor.OutputFormat)のいずれかが空の場合は、そのテーブルに対してクエリを実行すると次のようなエラーとなるので、テーブル作成時に忘れずに指定する必要があります。
HIVE_UNKNOWN_ERROR: Unable to create input format
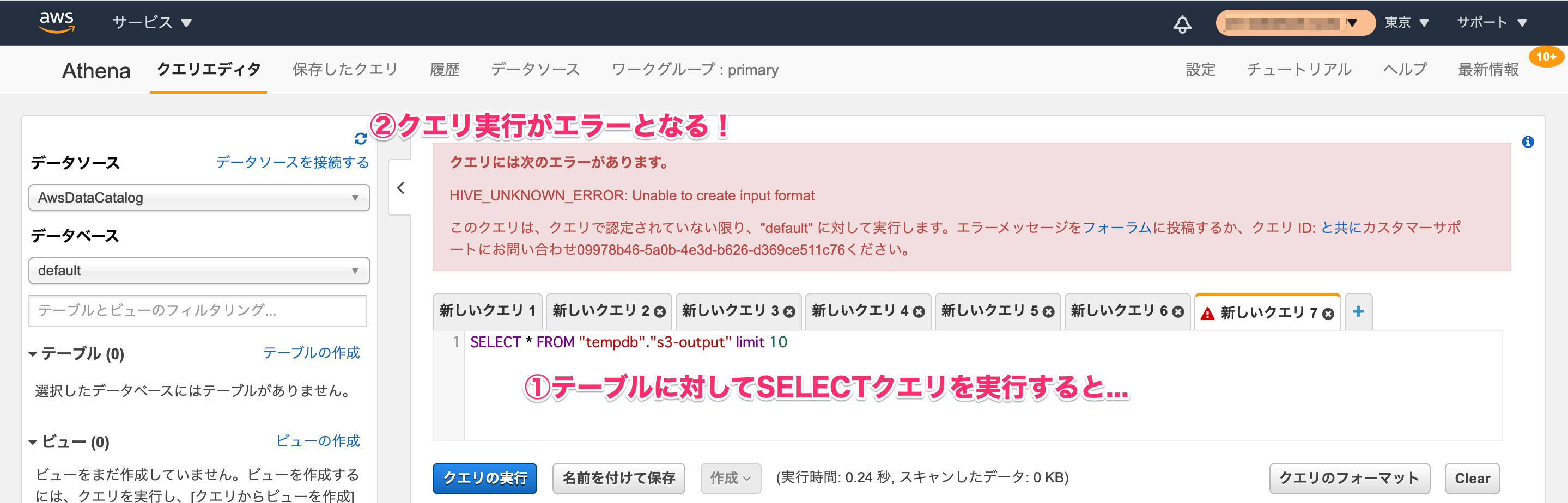
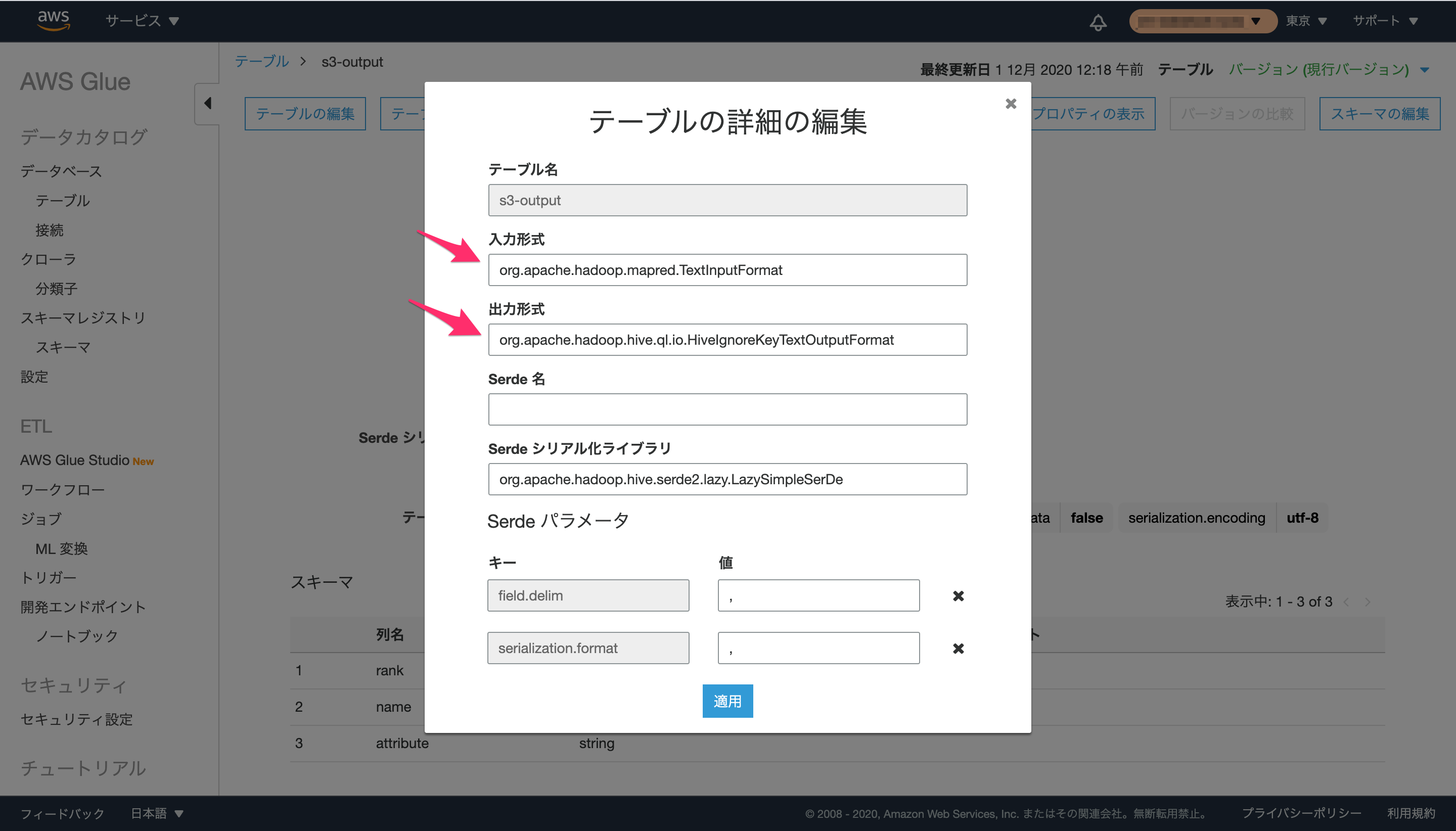
テーブルに設定されている入力フォーマットおよび出力フォーマットの値は、AWS Glueのコンソールの[テーブルの詳細]からも確認可能です。
Athenaでデータカタログへのクエリを実行する
ワークグループ作成(初回のみ)
Athenaでクエリを実行する際に、クエリの履歴を保存するワークグループが必要となるので、create-work-groupコマンドで作成します。
% aws athena create-work-group \
--name Data_Analyst_Group \
--configuration ResultConfiguration={OutputLocation="s3://<bucket-name>/query-result/"},EnforceWorkGroupConfiguration="true",PublishCloudWatchMetricsEnabled="true"
つまずきポイント
クエリ実行開始時にワークグループを指定しないと次のようなエラーとなるため、ワークグループを作成した上で--work-groupオプションで指定してあげる必要があります。
% aws athena start-query-execution --query-string "select * from tempdb.s3-output"
An error occurred (InvalidRequestException) when calling the StartQueryExecution operation: No output location provided. An output location is required either through the Workgroup result configuration setting or as an API input.
なお、Athenaのコンソールからクエリを実行する際は、既定で作成されているprimaryというワークグループが暗黙的に使われるので、明示的にワークグループを作成したり指定したりする必要は通常はありません。
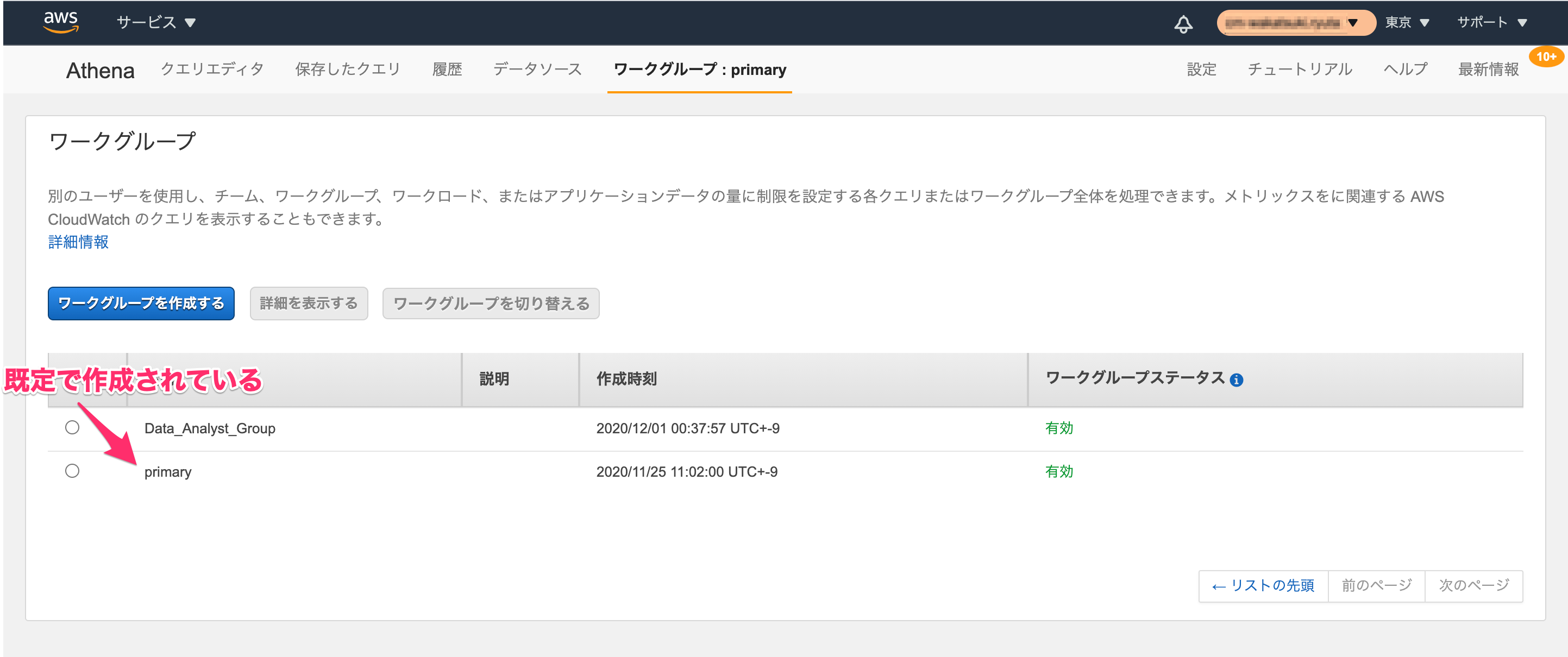
- ワークグループの仕組み - Amazon Athena
- Athena でクエリ実行時に”No output location provided ……”というエラーが表示された時の対処方法 | Developers.IO
クエリ実行の開始
start-query-executionコマンドでクエリの実行を開始し、クエリ実行IDを取得します。
% aws athena start-query-execution \ --query-string 'SELECT * FROM "tempdb"."s3-output" limit 10' \ --work-group Data_Analyst_Group
{
"QueryExecutionId": "632d7a7a-e9f2-46af-bd4b-08aa075a6ad2"
}
つまずきポイント
start-query-executionコマンドで指定するクエリ文字列では、データベース名とテーブル名を"で囲み、クエリ文字列全体を'で囲まなければコマンド実行がエラーとなります。
- 実行がエラーとなるパターン
% aws athena start-query-execution \ --query-string "select * from tempdb.s3-output" \ --work-group Data_Analyst_Group % aws athena start-query-execution \ --query-string 'select * from tempdb.s3-output' \ --work-group Data_Analyst_Group
次のようなエラーが出力されます。
An error occurred (InvalidRequestException) when calling the StartQueryExecution operation: line 1:15: mismatched input ''tempdb'' expecting {'(', 'ADD', 'ALL', 'SOME', 'ANY', 'AT', 'NO', 'SUBSTRING', 'POSITION', 'TINYINT', 'SMALLINT', 'INTEGER', 'DATE', 'TIME', 'TIMESTAMP', 'INTERVAL', 'YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'ZONE', 'FILTER', 'OVER', 'PARTITION', 'RANGE', 'ROWS', 'PRECEDING', 'FOLLOWING', 'CURRENT', 'ROW', 'SCHEMA', 'COMMENT', 'VIEW', 'REPLACE', 'GRANT', 'REVOKE', 'PRIVILEGES', 'PUBLIC', 'OPTION', 'EXPLAIN', 'ANALYZE', 'FORMAT', 'TYPE', 'TEXT', 'GRAPHVIZ', 'LOGICAL', 'DISTRIBUTED', 'VALIDATE', 'SHOW', 'TABLES', 'VIEWS', 'SCHEMAS', 'CATALOGS', 'COLUMNS', 'COLUMN', 'USE', 'PARTITIONS', 'FUNCTIONS', 'TO', 'SYSTEM', 'BERNOULLI', 'POISSONIZED', 'TABLESAMPLE', 'UNNEST', 'ARRAY', 'MAP', 'SET', 'RESET', 'SESSION', 'DATA', 'START', 'TRANSACTION', 'COMMIT', 'ROLLBACK', 'WORK', 'ISOLATION', 'LEVEL', 'SERIALIZABLE', 'REPEATABLE', 'COMMITTED', 'UNCOMMITTED', 'READ', 'WRITE', 'ONLY', 'CALL', 'INPUT', 'OUTPUT', 'CASCADE', 'RESTRICT', 'INCLUDING', 'EXCLUDING', 'PROPERTIES', 'FUNCTION', 'LAMBDA_INVOKE', 'RETURNS', 'SAGEMAKER_INVOKE_ENDPOINT', 'NFD', 'NFC', 'NFKD', 'NFKC', 'IF', 'NULLIF', 'COALESCE', IDENTIFIER, DIGIT_IDENTIFIER, QUOTED_IDENTIFIER, BACKQUOTED_IDENTIFIER}
- 実行できるパターン
% aws athena start-query-execution \ --query-string 'SELECT * FROM "tempdb"."s3-output" limit 10' \ --work-group Data_Analyst_Group
クエリ実行結果の取得
get-query-resultsコマンドを実行して、先程取得したクエリ実行IDから実行結果を取得します。
% aws athena get-query-results --query-execution-id 632d7a7a-e9f2-46af-bd4b-08aa075a6ad2
{
"ResultSet": {
"Rows": [
{
"Data": [
{
"VarCharValue": "rank"
},
{
"VarCharValue": "name"
},
{
"VarCharValue": "attribute"
}
]
},
{
"Data": [
{
"VarCharValue": "1"
},
{
"VarCharValue": "hojo"
},
{
"VarCharValue": "Co"
}
]
},
{
"Data": [
{
"VarCharValue": "2"
},
{
"VarCharValue": "sagisawa"
},
{
"VarCharValue": "Co"
}
]
},
{
"Data": [
{
"VarCharValue": "3"
},
{
"VarCharValue": "ichinose"
},
{
"VarCharValue": "Cu"
}
]
},
{
"Data": [
{
"VarCharValue": "4"
},
{
"VarCharValue": "kamiya"
},
{
"VarCharValue": "Co"
}
]
},
{
"Data": [
{
"VarCharValue": "5"
},
{
"VarCharValue": "takagaki"
},
{
"VarCharValue": "Co"
}
]
}
],
"ResultSetMetadata": {
"ColumnInfo": [
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "rank",
"Label": "rank",
"Type": "integer",
"Precision": 10,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": false
},
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "name",
"Label": "name",
"Type": "varchar",
"Precision": 2147483647,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": true
},
{
"CatalogName": "hive",
"SchemaName": "",
"TableName": "",
"Name": "attribute",
"Label": "attribute",
"Type": "varchar",
"Precision": 2147483647,
"Scale": 0,
"Nullable": "UNKNOWN",
"CaseSensitive": true
}
]
}
},
"UpdateCount": 0
}
これでS3上のデータに対してAthenaからクエリを実行できました。
おわりに
AWS Glueデータカタログへのテーブル作成とAthenaでのクエリ実行をAWS CLIでやってみました。
今までAthenaのコンソールから何となくでクエリコマンドを組み立ててクエリ実行していましたが、こうしてAWS CLIで一つ一つ自分で設定や実行をすることにより、AWS Glue含めてAthenaの仕様を学ぶことができました。
参考
以上







